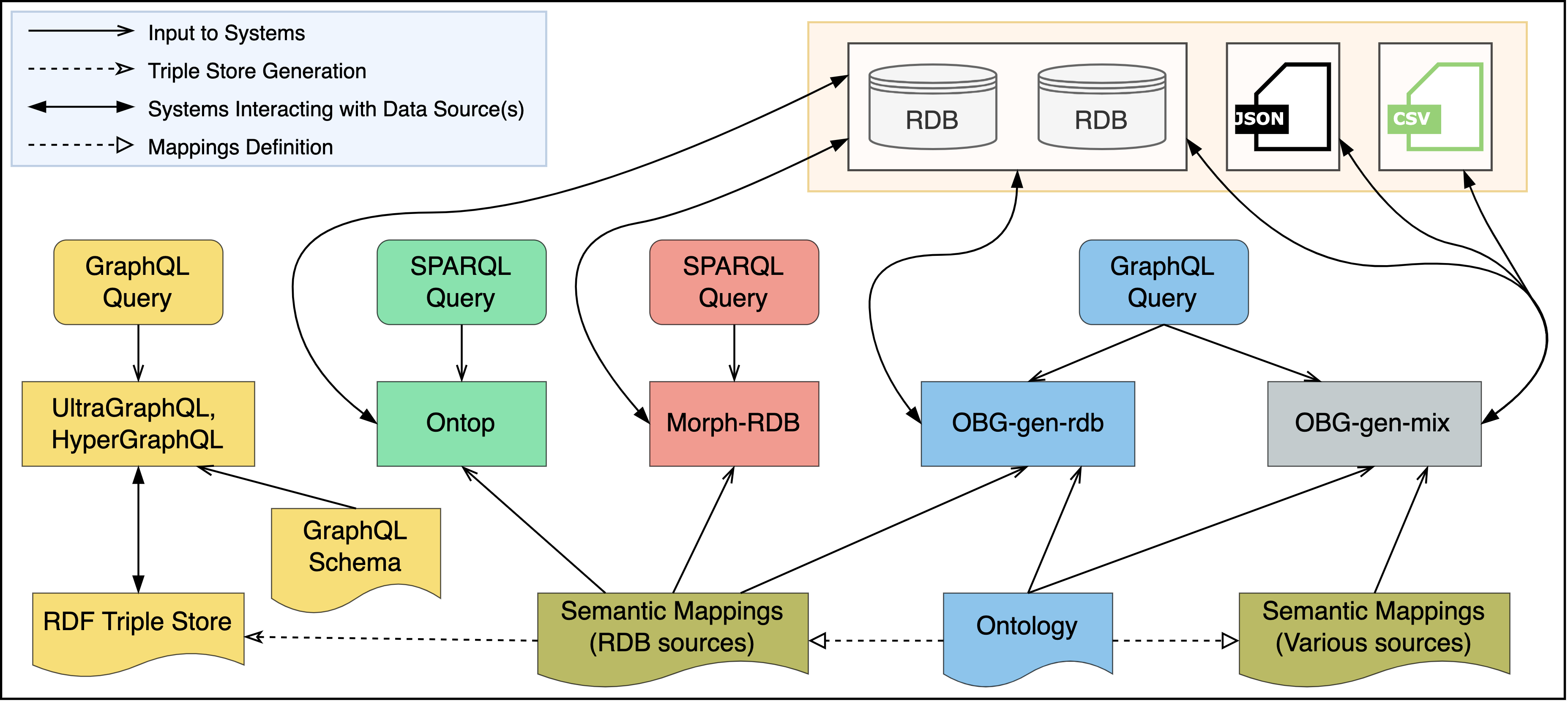
 Outline of the real case evaluation
Outline of the real case evaluation Evaluation in the Materials Design Domain
We compare our OBG-gen in two versions (OBG-gen-rdb and OBG-gen-mix) wih four systems: Morph-RDB, Ontop, HyperGraphQL and UltraGraphQL. OBG-gen-rdb represents the case where the generated GraphQL server handles data in relational databases, and OBG-gen-mix represents the case where the generated GraphQL server handles data not only in relational databases but also data in JSON and CSV formats.
GraphQL schema Data Example Query Execution Time per data size (queries without filter conditions)
Query Execution Time per data size (queries without filter conditions)Result and Discussion on Queries without filter conditions.
All of the systems have increases of QETs as the size of the dataset increases. However, Morph-RDB is less sensitive to the data size increase compared with other systems. UltraGraphQL and HyperGraphQL outperform other systems for some smaller datasets (e.g., UltraGraphQL's QETs of Q1 and Q2, HyperGraphQL's QETs for Q1 from 1K-1K to 4K-4K). We explain this by the fact that these two systems have additional context information declaring URIs of classes to which instances in the RDF data belong, which is unlike the other systems which have to make use of semantic mappings to output queries to be evaluated against the underlying data sources. OBG-gen-rdb outperforms Morph-RDB for some queries in smaller datasets (e.g., Q1 in 1K-1K, Q5 in 1K-1K and 2K-2K). For some queries, OBG-gen-rdb and Morph-RDB have close QETs (e.g., Q2 in 1K-1K). Ontop outperforms the other two in smaller datasets (e.g., Q1 in 1K-1K to 8K-8K, Q5 in 1K-1K to 4K-4K), but is more sensitive to data size increase compared with Morph-RDB.
Query example Query Execution Time per data size (queries with filter conditions)
Query Execution Time per data size (queries with filter conditions)Result and Discussion on Queries with filter conditions.
Ontop outperforms the other two engines for most cases, but is more sensitive to the change of datasets increase (e.g., Q9 from 1K-1K to 8K-8K). Ontop has a mapping optimization step which is not included in the query execution period. %This can be explained as the reason why Ontop outperforms the other engines. This could be a reason why Ontop outperforms the other engines. OBG-gen-rdb and Morph-RDB behave similarly for Q6 with stable QETs and Q12 with slight increases, as the data size increases. The result size of Q6 is a constant over all the datasets in different sizes. Additionally, the filter expressions for Q6 and Q12 are simpler compared with those of Q7--Q11. Therefore, the QETs for evaluating filtering expressions for Q6 and Q12 are less than those of Q7--Q11. For other queries (Q7--Q11) Morph-RDB outperforms OBG-gen-rdb, however the differences between the two systems are less than those for queries without filtering conditions (e.g., Q1--Q4). The filtering conditions in GraphQL queries for OBG-gen-rdb and in SPARQL queries for Morph-RDB are written within WHERE clauses in SQL queries, thus will be evaluated against the back-end databases.
Query example
Evaluation based on LinGBM
Same as the real case evaluation, we evaluate the query execution time (QET) of our system on the three datasets. Each query from a query set is evaluated once. Based on the obtained measurements, we observe that our system has slight increases for QS1, QS2, QS4, QS6 and QS7 in terms of the average QETs. For QS3, the average QET is stable for all the three datasets. For QT5, the increase from 0.51 seconds at data scale factor 20 to 13.85 seconds at data scale factor 100 is due to the dramatic increase in result size. More specifically, the queries in QS5 and QS8 need to access the 'graduateStudent' table which increases dramatically in size from 50,482 rows in the table (sf=20) to 252,562 (sf=100). This is the reason for the average QET of QS8 increasing in sf=100. Additionally, each query in QS5 repeats a cycle two times ('university' to 'graduateStudent' to 'university') and requests the students' emails and addresses along the way. This causes the larger increase in average QET of QS5. This synthetic experiments indicate that our system can work in another domain than the materials science domain.
GraphQL schema Query example Data Example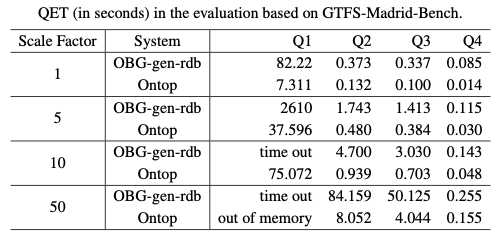
Evaluation based on GTFS-Madrid-Bench
According to the measurements, both OBG-gen-rdb and Ontop show increases in QETs for all four queries as the dataset increases. However, as with the observation in the real case evaluation, Ontop behaves less sensitively to the increase in dataset. In terms of how the two systems behave for different queries, both engines spend more time to answer Q1 (without any filter conditions). It takes OBG-gen-rdb more than 3,600 seconds to answer it for scale factors 10 and 50. Although Ontop is able to answer Q1 in less time than OBG-gen, it cannot finish the execution because it runs out of the reserved 4GB memory for scale factor 50. More specifically, Q1 needs to access the 'Shape' table which increases dramatically in size from 58,540 rows in the table (sf=1) to 292,700 (sf=5) and furthermore to 585,400 (sf=10) and 2,927,000 (sf=50). Both engines have relatively stable QETs for Q4 that retrieves all the route entities without any filter conditions. The corresponding 'Route' table is relatively small (e.g., 13 for sf 1 and 1,300 for sf 100). Q2 and Q3 retrieve all the station entities but with different filter conditions. The two engines spend more time to evaluate Q2 since the result size of Q2 is larger than that of Q3.
GraphQL schema Query example Data Example